
OpenAI 日报:ChatGPT 定时任务重做,生命科学研究连发
本期梳理 OpenAI 6 月 17 日至 18 日清晨的关键动态:ChatGPT Scheduled tasks 更新为可管理入口,LifeSciBench 与 AI 化学家实验结果同日发布,并跟进 Reuters 关于 Noam Shazeer 加入 OpenAI 与一季度现金消耗的报道。读者可快速判断哪些产品、研究、公司与运维信号需要继续跟进。

Research Brief
先看结论
6 月 17 日,OpenAI 的新增信息主要集中在三条线:ChatGPT 把「Scheduled tasks」做成更清晰的可管理页面,生命科学方向同时发布了 LifeSciBench 与一个 AI 化学家实验结果,公司层面则有关键人才与财务消耗的媒体报道。没有必要把所有小动态都放大;今天真正值得跟进的是:产品开始把「定时、监控、提醒」做成常规入口,研究线继续押注生命科学,资本市场叙事开始更关注现金消耗。
| 线索 | 本期事实 | 对读者的意义 |
|---|---|---|
| ChatGPT 产品 | OpenAI 在 6 月 17 日的 ChatGPT Release Notes 中更新了 Scheduled tasks:新增 Scheduled 页面,可查看任务下次运行时间,并暂停、恢复、编辑或删除任务;任务支持具体时间或「上午/下午/晚上」这类宽时间窗,监控类任务还能搜索网页并检查已连接应用;Plus、Pro、Business、Enterprise 用户开始获得该能力。1 | ChatGPT 的「主动提醒/定时监控」正在从实验体验转成可管理工作流入口,适合产品团队重新评估日报、竞品监控、个人提醒等场景。 |
| 研究评测 | LifeSciBench 包含 750 个专家撰写任务、1,062 个任务附件、173 位科学家贡献、19,020 条 rubric 标准和 453 位专家评审;OpenAI 称 GPT‑Rosalind 的整体 exact pass rate 为 36.1%,高于 GPT‑5.5 的 25.7%。2 | 生命科学评测开始从「答对生物题」转向「能否处理真实研发判断」,这比单项 benchmark 更接近企业采用前的能力验证。 |
| 实验科学 | OpenAI 与 Molecule.one 把 GPT‑5.4 接入 Maria 高通量实验室,围绕 Chan–Lam coupling 做近自主研究;项目运行 10,080 次反应,优化后平均产率从 16.6% 升至 25.2%,超过 30% 产率的反应比例从 15.6% 升至 37.5%。3 | 这是「模型—实验室—人类专家」闭环的具体案例,但 OpenAI 也明确承认它不是端到端自主科研,仍依赖专业实验基础设施和人工判断。 |
| 公司/人才 | Reuters 报道,Google 工程副总裁、Gemini 模型 co-lead Noam Shazeer 表示将离开 Google 加入 OpenAI。4 | 如果该任命落地,OpenAI 在前沿模型与大规模训练经验上的人才密度继续上升;但目前 Reuters 报道未披露具体岗位与团队归属。 |
| 财务信号 | Reuters 转述 The Information 称,OpenAI 2026 年一季度消耗 37 亿美元,收入为 57 亿美元;Reuters 同时说明未能立即独立核验该报道。5 | 这条不是官方披露,不能当作已核验财报;但它会影响外界对 OpenAI 上市前资本效率和算力支出的讨论。 |
| 服务状态 | OpenAI 状态页显示,FedRAMP workspaces 和 API orgs 的 degraded performance 仍在调查;同日 Android 与 iOS conversations elevated errors 已恢复。6 7 | 企业和政府合规环境的用户仍需单独看 FedRAMP 状态;普通移动端会话错误已不是当前主要风险。 |
ChatGPT:Scheduled tasks 变成可管理入口
这次 Scheduled tasks 的变化不是一个单点按钮,而是把任务管理集中到侧边栏可发现的 Scheduled 页面。用户可以看到活跃任务、下次运行时间,并对任务执行暂停、恢复、编辑、删除等操作。OpenAI 还强调,任务会变得更快、更可靠,并支持「某个具体时间」或「上午/下午/晚上」这类宽时间窗。1
更值得注意的是监控任务:OpenAI 写明,这类任务可以搜索网页、检查已连接应用里的变化,并只在有值得报告的内容时通知用户。对团队来说,这更接近轻量 agent 的日常入口,而不是普通提醒事项。当前限制也要记住:任务不能超过每小时运行一次,且无人照看的任务可能在一段不活跃后自动暂停。1
OpenAI 同时宣布 Pulse 将随主动更新能力迁移到 Scheduled tasks 而 sunset,Pro 用户还能继续使用 14 天。这个细节说明产品重心正在从一个单独的 proactive feed,转向由用户显式配置的定时任务和监控任务。1
生命科学:一个评测,一个实验闭环
LifeSciBench 的定位,是评估 AI 系统能否处理真实生命科学研究任务,而不是只回答干净的生物知识题。OpenAI 把任务划分到 evidence handling、analysis、design and optimization、scientific reasoning、validation and operations、translation、scientific communication 七类工作流,并强调 79% 的任务需要多步推理或决策,53% 的任务要求模型解释或综合至少一个附件。2
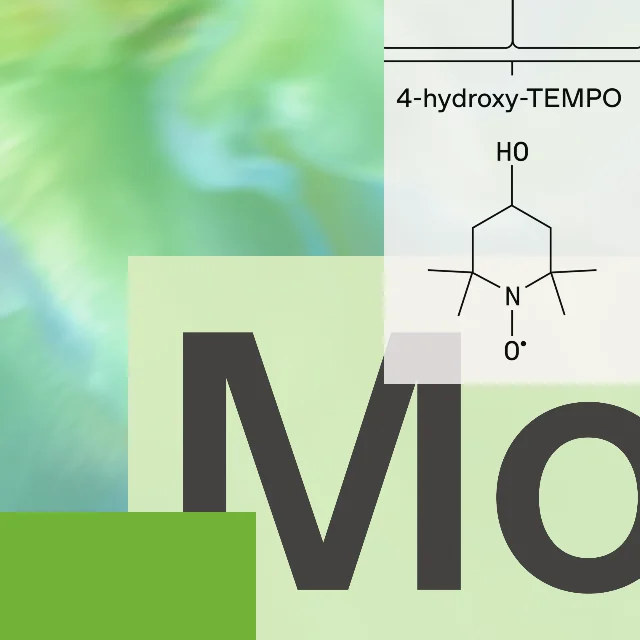

结果部分同样值得克制解读。OpenAI 称 GPT‑Rosalind 相比 GPT‑5.5 有进步,但绝对 pass rate 仍不高;尤其在带附件或 URL 的任务上,GPT‑Rosalind 的 pass rate 从 text-only 的 45.1% 降到 28.1%。这句话比「模型很强」更重要:真正的研发工作通常有图、表、序列、PDF、实验记录,模型短板也常出在这些材料的抽取与整合上。2
同一天的 AI 化学家项目,则提供了一个更接近「科学工作流」的样本。OpenAI 与 Molecule.one 把 GPT‑5.4 接入 Maria,系统生成研究提案、设计并运行实验、分析数据、提出后续实验;人类科学家负责编写 steering/grading prompts、选择进入实验的方案、做有限实验计划修正,并独立验证最终结果。3

这里最有信息量的数字是 10,080 次反应,以及 bench scale 上 14 对代表性 substrate pair 中有 11 对产率提高,其中 8 对提升超过两倍。它说明模型不是只写了一段化学建议,而是进入了「假设—高通量实验—结果分析—人工验证」链条。OpenAI 也写得很清楚:这不证明 AI 可以独立运行完整化学研究项目,结果还需要独立复现,并且不应被解读为模型能帮助有害化学应用。3
公司信号:人才流动与现金消耗同时进入视野
Reuters 报道称,Google 工程副总裁、Gemini 模型 co-lead Noam Shazeer 将离开 Google 加入 OpenAI。当前报道很短,信息密度集中在「谁」和「去哪里」,尚未披露他在 OpenAI 的具体职责。对 OpenAI 观察者来说,这条更像一个人才密度信号:前沿模型组织之间的关键研究/工程人才流动还在继续。4
另一条财务线索需要更谨慎。Reuters 转述 The Information 称,OpenAI 一季度消耗 37 亿美元,收入 57 亿美元,并说明 Reuters 无法立即独立核验。这个信息如果与此前 OpenAI 已秘密提交美国 IPO 文件的背景放在一起看,会强化市场对算力、研发和商业化效率的追问;但在 OpenAI 没有正式披露前,它只能作为媒体转述信号使用。5
运维提示:FedRAMP 仍未恢复,移动端问题已解决
状态页上,FedRAMP workspaces 和 API orgs 的 degraded performance 仍处在 investigating 状态;而 Android 和 iOS 设备上的 conversations errors 已标记为 resolved。6 7
这对不同用户的含义不一样:普通移动端用户可把 6 月 17 日的会话错误当作已恢复事件;政府、合规企业或依赖 FedRAMP 环境的团队,仍应把状态页放进当天排障清单,不要只看主站整体可用性。
今天怎么跟进
References
- 1ChatGPT — Release Notes
- 2Introducing LifeSciBench
- 3A near-autonomous AI chemist improves a challenging reaction in medicinal chemistry
- 4Google's Gemini co-lead Noam Shazeer to join OpenAI
- 5OpenAI burned $3.7 billion in first quarter of 2026, The Information reports
- 6FedRAMP workspaces and API orgs have degraded performance
- 7Errors with conversations on Android and iOS devices
Add more perspectives or context around this Post.